Member-only story
A Beginner’s Guide to the CLIP Model
How It Brings Images and Text Together

What is the CLIP Model, and Why Is It Important?
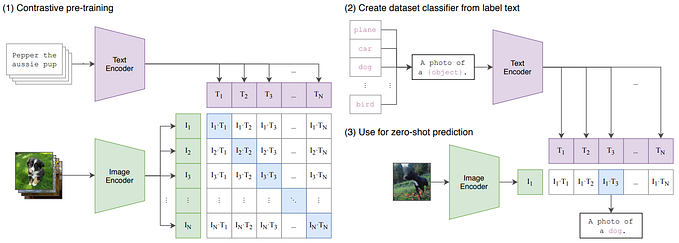
The CLIP model, developed by OpenAI, is a tool that helps computers understand images and text together. Instead of needing specific training for each task, CLIP uses natural language (like descriptions or captions) to recognize and categorize images. This makes it incredibly flexible — it can handle new tasks right away, which is what we call “zero-shot” learning. With CLIP, we get one step closer to a more general-purpose AI that can understand different types of information together.

How Does CLIP Work?
CLIP learns by matching images with their corresponding text descriptions. Think of it like a game of “match the image with the caption.” It does this using something called contrastive learning. During training, it looks at millions of image-text pairs (for example, an image of a dog with a caption that says “a happy dog in a park”) to figure out how images and words relate to each other.